Moving to Cloud has not been always easy, much less if you live in a industry traditionally hardware centric and inherently non-cloud native as Telco industry is.
Moreover, once you are there or even before, a new necessity seems to appear: Orchestration. But wait, orchestrate what and why now?
An official answer could be:
- What needs to be orchestrated: Of course the workloads you put on the cloud execution environments, no matter these are IaaS, CaaS1, located on premise or in public cloud. Recently, not only the workloads but also the cloud execution environment itself, has become Orchestration dependent. Specifically the CaaS world has brought a new challenge. It is very common to require multiple CaaS clusters to deploy your containerized workloads even inside the same location: welcome to the one App, one K8s cluster hell. Therefore, the creation and management of these clusters where the workloads live, need also to be orchestrated if you do not want to be burnt in this multi-cluster hell.
- Why now: Well, in fact this is something you should have done even before cloud. At least if you consider yourself a modern and efficient organization. But now, with your assets running in the cloud, is when the real potential of Orchestration can dazzle your operation teams and your finance departments. Combining Orchestration and Cloud should be in the Universal Declaration of Machine Rights :-). The reason: once the workloads are in the cloud is not hard to have a topological map and a handful of “magic buttons” to configure them, move them, heal them, upgrade them or even kill them. The paradise of automation and savings.
So I am in, of course. I am working in a Network Service Provider with a really big and complex infrastructure with dozens or thousands2 points of presence, I cannot dismiss to build Orchestration. Let’s do it, we only need to discover How to do it
The first thing to do is to check if we really need to invent anything new. Around Cloud Services there are tools or components specifically designed to deploy or manage the workloads. IaaS and CaaS have some well known components broadly adopted by the industry. Let’s talk briefly about HEAT and HELM.
HEAT is a component present in the OpenStack project3 since 2012 and operates in the IaaS world. HELM is not really known as an orchestrator but as a package manager. It was created in 2015 around CaaS world and is a de-facto standard there. But essentially both works the same way and serves well to orchestrate your workloads in both worlds.
They use the concept of descriptor: a file or group of files written with an specific language4 and with an specific format. These files contain the description of the stack your workload is built with. The stack is the collections of objects representing the compute, storage and connectivity resources your deployment have. For example a serie of Virtual Machines, Containers, Volumes, Virtual Networks, Services connected to a Cloud Load Balancer, etc. Among these files there are some special, the numbered with number 1 in the figure. They do not really contain the topology of your workload which is in turn described in files numbered as 2 in the figure. They just contain the so called instance parameters5: data. These are network addressing, sizing, policies, naming rules and others that can be different for each “instance” you created of an specific Application or Network Function. Typically, in a telco environment, you never have a single instance of an Network Function serving the whole Network Service. At least two instances are created, depending on the service and network topology. A geographical distribution of instances is a very common example with some instances serving part of the territory and others the rest. At the end Application or Network functions vendors usually deliver these descriptors as a part of the software package that includes also the binaries with the application logic itself and, with that in your hand, you design your network instantiating several Network Function instances.
Technically you use these descriptors injecting them over the corresponding controllers, whether HEAT or HELM, via API or command line. Once injected the controller interpret them and “speaks” with the API of the infrastructure to build the resources with these specific instance parameters. And once built – we are being so lucky until now, no errors found anywhere 🙂 – you can use the same descriptors altering them to update the already created resources, upgrade them, scale them,.., piece of cake!.

Unfortunately there are limitations. First is very basic. Neither of these solutions are conceived to operate among different clusters or points of presence of the infrastructure. Let me explain this. There is not a “field” in the HEAT template nor in HELM chart that translate to “put this stack in the cluster#2 of Seville area but this other in the cluster#1 of Barcelona area”. Second obvious limitation is that both are “solution specific”, one for Openstack IaaS, the other for Kubernetes CaaS. Maybe you do not need more but…
Here is were the “inventors” of the cloud may have something. Of course I am talking about the big three, Amazon AWS, Google Cloud Platform and Microsoft Azure. And eureka, they have something. Their clouds serve hundred of thousands of customers with their corresponding workloads. Is naive to think these hyperscalers do not have a powerful Orchestration layer to enable self provisioning for their customers and tools to manage the rich catalogue behind their portfolio. And there it is, the big three have their own Orchestration Tools and these tools overcomes the limitations noted before to HEAT and HELM. They are able to manage the workloads over their Regions and/or Avalability zones and for a set of virtualization platforms like IaaS and CaaS. Great! It is already invented!

But wait again. There is trick here. In these solutions the descriptor languages are propietary and the they do not cover hybrid cloud paradigm. The latest is something obvious but relevant. You cannot use AWS descriptors and tools to manage your workloads over Google Cloud Platform and viceversa. Or Azure descriptors to deploy your Applications over your lovely Redhat or VMWare Cloud on premise solution. We are vendor locked in so it is time to knock on Standardization Bodies door. Call it ETSI NFV6.
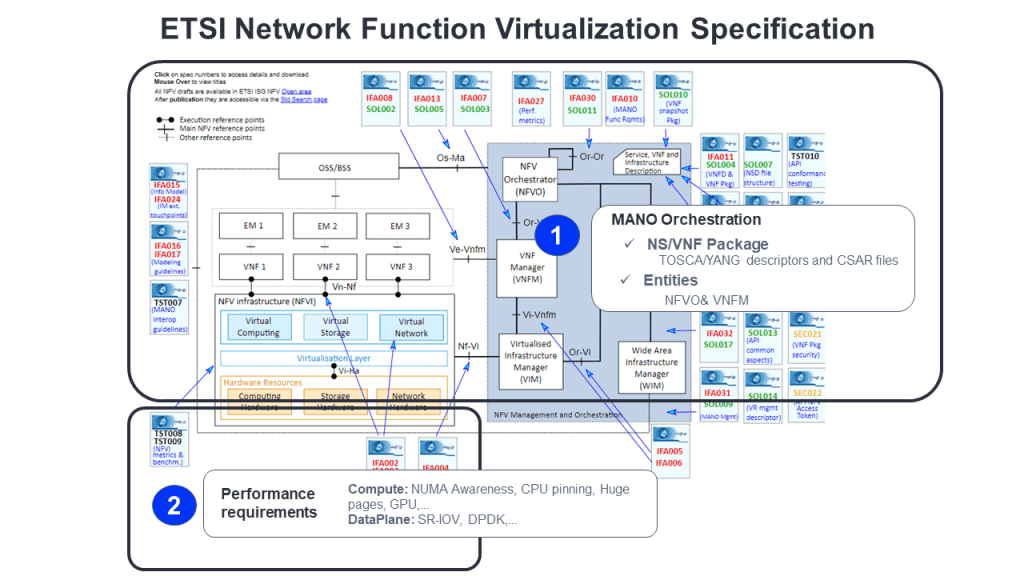
ETSI NFV tried to tackle this problem from the very beginning of its existence in 2010. In fact almost the entire specification effort is related with Orchestration as you can see in the following figure. All the stage 37 specs SOLXXX an almost all stage 2 IFAXXX are related to MANO: Management and Orchestration. Moreover ETSI NFV initiated the first open source project in its history, the so called OSM: OpenSource MANO which is an opensource Orchestrator of course.
But before going deep in ETSI MANO let’s position this entity in the whole ecosystem. Because again: the solution was not really new or better said, ETSI MANO has not been always alone. There have been projects more or less linked with ETSI MANO that are trying to solve the same problem. The first is TOSCA: coming from oasis-open.org and the linux world. TOSCA means Topology and Orchestration Specification for Cloud Applications and was in fact chosen by ETSI NFV as the language of descrption for the workloads.
The idea behind all of them is simple: define a non proprietary method of packaging Cloud Applications or Network Services for the SW vendors and a framework to interact with the cloud infra providers APIs. Then you will have an Orchestrator that can import that packages fron any compliant vendor and deploy your Application or Network Service instances all over the Cloud World, as your choice. There are others projects now, like Terraform, but let focus in ETSI.

What makes ETSI MANO special for telco industry? If we look closely to ETSI MANO the real wonder behind is the coordination with the cloud execution environment API and the management interface of the Network Function itself. ETSI MANO call them IFA006 and SOL002 interfaces respectively. With these two interfaces the virtual resources of your stack can be created (day-0) using IFA006 and then managed (day-1&day-2) using IFA006 and/or SOL002. More specifically ETSI MANO defines two entities and five new interfaces to implement it. Sorry, I said ETSI is and standard body but this does not mean things would be simple :-). These are NFVO and VNFM. Let’s try to clarify responsibilities:
- NFVO is the Orchestrator of a Network Service which in turn is composed of one or several Network Functions plus the connectivity between them. It uses the SOL003 interface against the VNFM to create and manage Network Function instances. And also IFA005 to learn some Cloud Infraestructura info like quotas use and others. Aditionally we have a powerful interface: SOL017, the one NFVO uses to create multi-site connectivity between Network Functions. There is real magic behind this interface , call It WAN controller or even SDN adapter if you want to be more trendy8.
- VNFM is the one in charge of interacting with the cloud execution APIs9 using IFA006 to create&manage the stack of virtual resources and with the Network Function instances management interface using SOL00210

It seems quiet complicated but you should admit that if every interface and entity logic work fine this is real Nirvana.
But ETSI had not finished yet. They showed some kind of weakness or flexibility, depending on your point of view, with the VNFM element. They declared two categories of VNF Manager implementation:
- Generic VNFM, speaks all the defined SOLxxx and IFAxxx standard interfaces, great!. At least great if all the others elements do the same.
- Specific VNF. Do not mind if some of the elements do not speak standard interfaces. I am here to solve! Great again! Or not.
Specific VNFM is a trap for vendor lock-in. Those vendors of cloud infra or Network Functions that do not support the standard interface will be awarded with you buying their Specific VNFM solution. Imagine you have the money and full automation do the business case. Wait again! Please consider this before doing your complete business case:
- IFA006 is an stage 2 or not fully defined interface. This S-VNFM have to get alone with your cloud execution environment APIs. You should not take it for granted. Better if you do not mix different vendors for now
- Cloud Native Network Functions or CaaS world. This is the future and please notice: in this world if your Network Function vendor is really cloud native SOL002 is useless, everything should be possible to be done through K8s core APIs or other de facto standards. Probably the entire MANO building would be done because other techniques like GitOps can compete well with it. So do not put many years in the business case please.
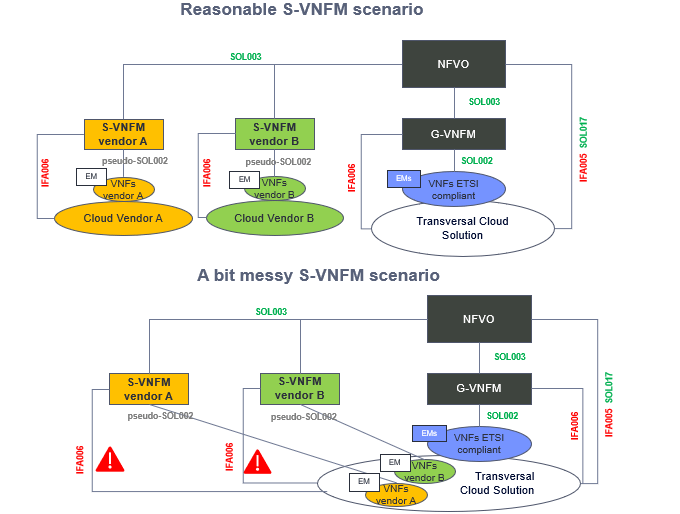
To be fair, Generic VNFM has also its drawbacks, SOL002 is currently a myth, at least I have not ever seen any Network Function or the corresponding Element Manager implementing it. So in the interim, if you need this fully automation you need to make some proprietary adaptation in your G-VNFM. Call It Network Function adapter or pseudo-SOL002 implementation. To do this at reasonable cost ask your Network Function vendors to provide all the needed artifacts or libraries used in their S-VNFM. If they do not accept these terms call the police, you are being blackmailed 🙂
And a final warning: there is another trend in industry which is called the E2E Orchestrator. An Orchestrator on top of several “domains orchestrators”, Do not be confused, this concept does not fix the S-VNFM issue so do not waste your money or your neurons at least you are trying to solve a different problem.
See you soon!
- Remember: IaaS is site or sites where you can run virtual servers also called virtual machines with the same functionality as if they were physical servers. CaaS is the same concept but with this new crazy thing called Containers= somehow mini-virtual machines with a control plane really intelligent and fast. ↩︎
- Depending on what network plane is in the scope of the cloud the numbers could be immense. From core network to fixed access or radio access networkrk there is a tremendous difference ↩︎
- Openstack comes from 2010 and was initially a NASA project later put in the hands of opensource community. Is one of the de facto open standards in the IaaS business and competes with others like VMWare IaaS. ↩︎
- YAML is the winner here ↩︎
- This is the values.yaml file in HELM and tipically the environment.yaml file in HEAT ↩︎
- ETSI NFV is a standardization group formed in 2010 ↩︎
- In ETSI, specifications at stage 3 are finished. It means you have a document with all the details needed to develop a node, an interface, a service, whatever. Stage 2 means they are defined but not at low level so great flexibility appears ↩︎
- This is really difficult to achieve in complex transport networks ↩︎
- API Openstack or API K8s typically ↩︎
- SOL002 can be a direct interface against the VNF management interface or indirect interface through the Element Manager (EM) of this VNF. Does not really matter ↩︎

Leave a comment